Profiling on Social Networks with Topic Modeling
June 2019 - Alberto Pou
Last weekend, I built an application for analyzing Twitter timelines called Profiler. Some years ago, while working on probabilistic models, one caught my attention: Latent Dirichlet Allocation (LDA).
This model was developed by David Blei, Andrew Ng, and Michael I. Jordan to discover topics in document collections. In other words, it groups text documents into topics that the model discovers automatically. I won’t explain the model structure and inference here. For that, I recommend reading the original paper.
LDA is based on estimating Dirichlet distributions, which model the probability of membership in a set of classes. The model constructs Dirichlet distributions through an iterative procedure to estimate the probability of a word belonging to a specific topic and the probability of each document belonging to each topic. The parameters of these distributions can be estimated using various Bayesian inference techniques, such as Variational Inference or sampling methods like Markov Chain Monte Carlo.
Profiler uses this probabilistic model to identify topics in a Twitter timeline: a collection of user tweets. The application downloads all tweets from a user, stores them, preprocesses them, and discovers their main topics.
Technology Stack
- Data Collection: Tweepy for downloading Twitter data
- Storage: MongoDB with PyMongo for storing timelines
- Preprocessing: Pandas and NLTK for cleaning tweets (removing emoticons, symbols, and digits; converting text to lowercase)
- Model Inference: Gensim for a concurrent LDA implementation
- Visualization: pyLDAvis for generating interactive visualizations to explore results
- CLI: Google’s Fire library for the command interface
- Development Environment: Docker, Docker Compose, and Travis CI for automated testing
Command Interface
Profiler has a simple command interface. For example, you can analyze Spanish politicians with:
make run_all timelines=Albert_Rivera,sanchezcastejon,Pablo_Iglesias_,pablocasado_ n_topics=5Installation steps are available in the repository README. You can configure preprocessing and model parameters in the settings file.
Example Results
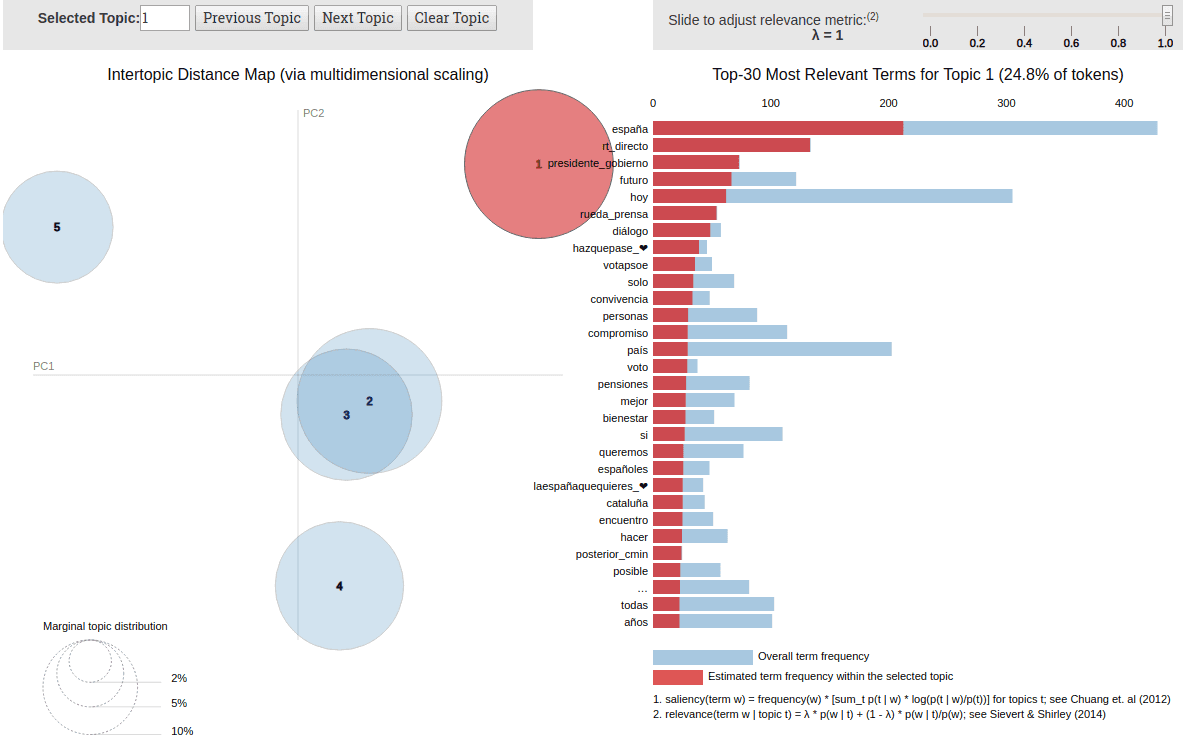
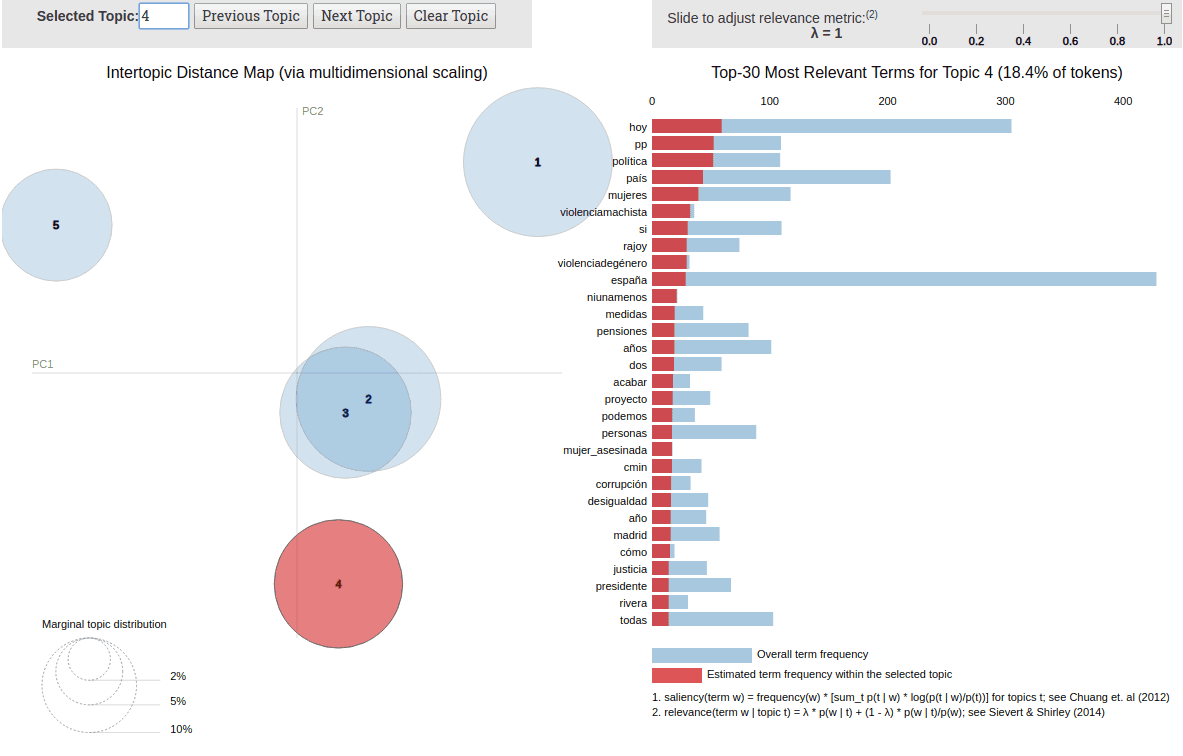
Results from Twitter data aren’t as clear as those from longer documents like articles or blog posts. Tweets are short, resulting in limited vocabularies that make it harder for the model to identify distinct topics (a problem known as data sparsity). However, the example above shows some interesting patterns. These results are from Pedro Sánchez’s timeline (President of Spanish Government). Group 1 appears to relate to campaign tweets, while Group 4 focuses on the issue of gender-based violence.
Despite these challenges, LDA proves to be a powerful tool for unsupervised analysis of social media. It allows us to quickly grasp the main themes in a user’s discourse without manually reading thousands of tweets. With further refinement, such as aggregating tweets by user or time windows, the coherence of these topics could be improved even further.
References
- David M. Blei, Andrew Y. Ng, and Michael I. Jordan. 2003. Latent Dirichlet Allocation. J. Mach. Learn. Res. 3 (March 2003), 993–1022.